背景阅读
我将在下面使用的技术来构建我们的第一个示例模型是在教科书的第二章中开发的。在尝试详细理解这个例子之前,您应该先阅读那一章。
骑行模式
对于我们机器学习模型的第一个例子,我将构建一个简单的线性回归模型,该模型可以根据一些输入特征(如温度和风速)预测骑自行车的平均速度。
我有一条最喜欢的骑行路线,如下图所示。
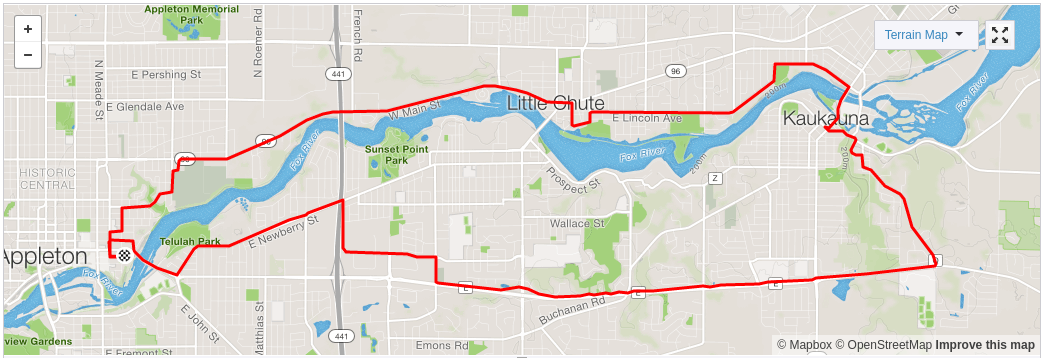
每次我骑自行车的时候,我都会用GPS设备记录我的路线。随后,我将GPS文件上传到strava.com,这样我就可以保存赢博体育骑行的记录。
由于每次骑行的条件都不一样,我在这条路线上的平均速度在一年中会从14英里每小时的低到17英里每小时的高。在我们机器学习的第一个练习中,我将建立一个简单的模型,它可以预测路线的平均速度,作为各种因素的函数,这些因素可能在决定平均速度方面发挥作用。
由于我经常骑这条路线,所以我收集了足够的骑行数据,可以建立一个简单的数学模型。我有从2016年到2017年收集的50次自行车骑行的数据。这些数据足以开始构建一个简单的模型来预测我的平均速度。
建立模型
建立数学模型的第一步是写下对模型输出有一定影响的特征列表。对于这个例子,我们试图预测骑自行车的平均速度。以下是一些可能影响结果的因素:
- 骑自行车的人可以产生多少动力:一个强大的骑自行车的人会骑得更快
- 用于骑行的自行车:一辆轻便、快速的自行车可以让骑行速度更快
- 路线的难度:丘陵路线比平坦路线的平均速度要低
- 骑行时的温度:寒冷天气骑行会比温暖天气骑行慢
- 风速和风向:强烈的逆风使骑行速度变慢
模型构建的一般规则是,具有更多输入特征的模型将比具有更少输入特征的模型需要更多的数据点。科学中常用的策略是控制实验:在控制实验中,我们修复尽可能多的特征,以努力减少我们必须处理的输入特征的数量。对于这个特殊的例子,我将尝试保留尽可能多的固定特征,以减少我们必须处理的输入数量。下面是我为减少这个问题的输入特征的数量所做的。
- 因为我在这个例子中使用的赢博体育数据都是由我生成的,所以作为第一个近似,我们可以假设数据集中的赢博体育游乐设施的特征1都是固定的。
- 每次骑车我都用同一辆自行车。然而,我确实使用了两种不同的车轮组:在温暖的天气里,我使用了一组相对较轻的车轮,在凉爽的天气里,我换成了一组较重的车轮和较硬的轮胎。自行车类型的变化将通过数据集中的一个特征来捕获,该特征将0分配给较轻的车轮组,将1分配给较重的车轮组。
- 数据集中每次骑行使用的路线是相同的。可能影响这条线路速度的一个小因素是,2016年至2017年这条线路略有变化。2016年底,高速公路部门在其中一个十字路口安装了一个环形交叉路口。由于在安装了环形交叉路口后,我不得不放慢速度,这对我在这条路线上的平均速度有一个很小但明显的影响。这种差异将通过数据集中的年份列来捕捉,该列表明给定的骑行是发生在2016年的快速路线上还是2017年的慢速路线上。
随着这些特征或多或少保持稳定,输入数据集现在由五个输入特征组成:
- 年份:2016年或2017年
- 车轮类型:1为重,慢轮和0为轻,快轮
- 温度
- 风速
- 风向
收集数据
该模型的输入数据来自两个数据源。第一个数据源是从strava.com下载的GPX文件集合。这些文件包含了我在2016年和2017年每次骑自行车的GPS数据。每次骑行的GPS数据都是以一长串在骑行过程中获取的GPS坐标的形式呈现的。对于数据集中的每次骑行,该文件记录一个时间戳、纬度、经度和海拔(以米为单位),在骑行过程中每4秒记录一次。第二个数据源是一个电子表格,其中包含来自国家气象局的天气数据。该电子表格记录了从2016年初到2017年底,阿普尔顿机场每20分钟记录一次的大量天气数据。
任何机器学习项目的第一步都是数据整理。我们必须获取我们所拥有的原始输入数据,并将其重组为我们想要的特征的一组数据点。为了处理这部分任务,我编写了一个Python程序strava.py,它将聚合来自GPX文件和天气数据电子表格的数据。有关此Python程序如何工作的更多详细信息,请参阅Read Me文件和Python程序中的注释。
数据争用集的最终结果是一个CSV文件short_rides.csv,其中包含我们模型的输入数据。
由于在本例中,我们将更多地关注模型构建而不是数据争用,因此在此我不会详细注释Python程序中的代码。当我们准备为最终项目做一些进一步的机器学习项目时,我们可能会在本教程后面重新讨论这些代码。
构建和测试模型
数据集就绪后,我们就可以开始构建模型了。这个过程的全部细节可在Jupyter笔记本线性。Ipynb包含在下面的存档中。
模型的文件
循环模型的赢博体育文件都可以在此存档中获得。